Parsers
Comment exploiter efficacement du texte brut
https://blemoine.github.io/parser-prezQui suis-je ?
- Benoît Lemoine
- Développeur chez BusBud
- Co-Organisateur Montreal TypeScript meetup
- https://lemoine-benoit.medium.com/
- @benoit_lemoine

Le PO a une super idée!
En tant qu'utilisateur, je veux écrire des formules à la excel pour manipuler le tableau de données dans l'application
ChatGPT?
Answer only with the result, give no explanation.
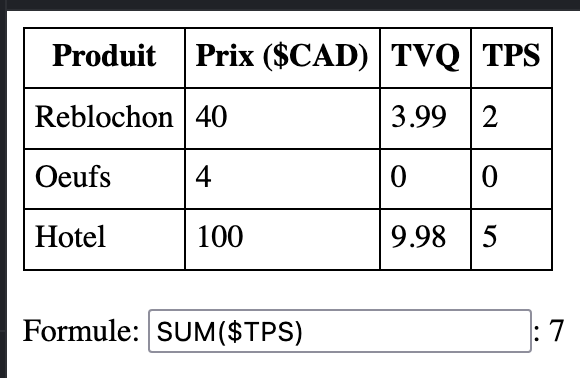
Given the following JSON data
```
{
"header": ["Produit", "Prix", "TVQ", "TPS"],
"rows": [
["Reblochon", "40", "3.99", "2"],
["Oeufs", "4", "0", "0"],
["Hotel", "100", "9.98", "5"]
]
}
```
Give the result of the formula `SUM($TPS)`
7Ca fonctionne! Ca y est story implémentée!
Est ce que ca fonctionne?
Answer only with the result, give no explanation.
Given the following JSON data
```
{
"header": ["Produit", "Prix", "TVQ", "TPS"],
"rows": [
["Reblochon", "40", "3.99", "2345678"],
["Oeufs", "4", "0", "0"],
["Hotel", "100", "9.98", "987654321"]
]
}
```
Give the result of the formula `SUM($TPS)`
987657999Le vrai résultat est
989999999Pourquoi ca ne fonctionne pas ?
|
To
From
|
Langage naturel | Langage formel |
|---|---|---|
| Langage naturel | ChatGpt | ChatGpt |
| Langage formel | Développeur | Parser |
Autres exemples de cas d'usage pour parsers
-
Supporter un sous/sur ensemble d'un langage existant
{"name": "Georges" /* JSON with comments */} -
Interface Utilisateur permettant de saisir des commandes
/invite @georges -
Valider (et simplifier) un fichier de configuration
frequency: every friday - Créer son propre DSL/Langage de programmation (sql, markdown, coffeescript, ...)
- etc.
Qu'est qu'un parser, en pratique ?
String =>
Concrete Syntax Tree*
Concrete Syntax Tree ?
CST aka Parse Tree
Représentation sous forme d'arbre d'une expression
1 + 2 * 3Expression(Number(1), Operator('+'), Expression(Number(2), Operator('*'), Number(3)))Abstract Syntax Tree
AST
Représentation des parties signifiantes de l'expression
1 + 2 * 3add(1, multiply(2, 3))Pour un AST plusieurs CST
multiply(2,3)-
2 * 3
Expr(Number(2),Operator('*'),Number(3)) -
* 2 3
Expr(Operator('*'), Number(2),Number(3)) -
2 3 *
Expr(Number(2),Number(3), Operator('*')) -
two times three
Expr(Number('two'),Operator('times'),Number('three')) - etc.
Syntaxe != Sémantique
let x: boolean = 23;
Comment implémenter un parser ?
Les solutions... discutables
evalet langages DSLables (ex. scala ou groovy)- Lié fortement à une plateforme
- Difficulté à valider les entrées
=>problémes de sécurité - Limitation des grammaires possibles
Hiérarchie de langage de Chomsky
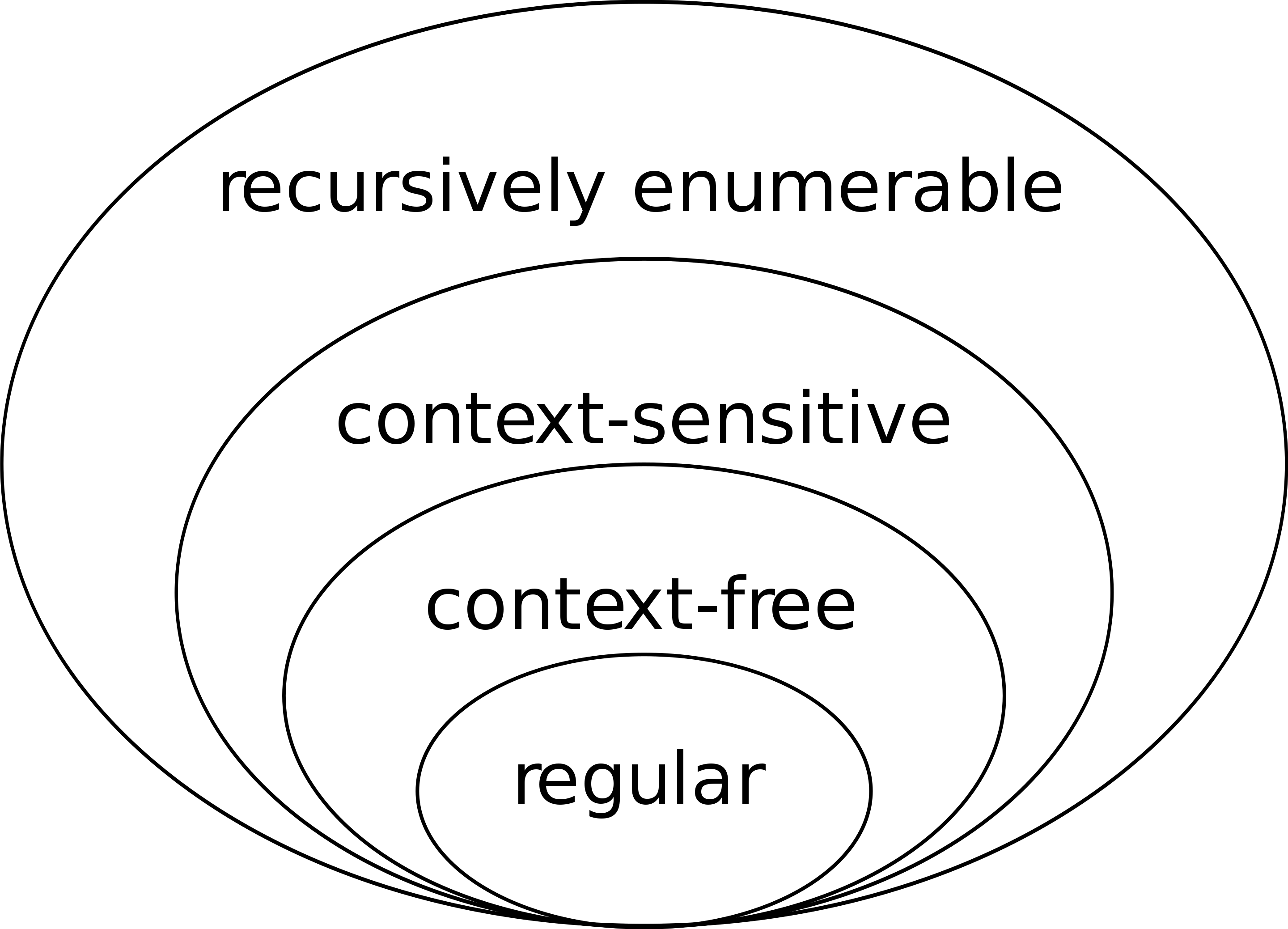
Examples
- Régulier
123546.5434 - Non contextuelle
( 1 + 2 ) * 3 - Contextuelle
T * x; - Récursivement énumérable
Créer son langage ?
- Essayer d'être le plus simple possible
- Limiter les espaces sémantiques
- Avoir des marqueurs de début ET de fin
Parser un langage régulier
Utiliser les expressions régulières - aka Regex
- Code Postaux au Canada
K1A 0B1ouH0H 0H0-
[A-CEGHJ-NP-TVXY][0-9][A-CEGHJ-NP-TVXY] [0-9][A-CEGHJ-NP-TVXY][0-9]
PAS DE REGEX POUR LES LANGAGES NON CONTEXTUEL
a mere glimpse of the world of regex parsers for HTML will instantly transport a programmer's consciousness into a world of ceaseless screaming, (...) ᵒh god no NO NOO̼OO NΘ stop the an*̶͑̾̾̅ͫ͏̙̤g͇̫͛͆̾ͫ̑͆l͖͉̗̩̳̟̍ͫͥͨe̠̅s ͎a̧͈͖r̽̾̈́͒͑e not rè̑ͧ̌aͨl̘̝̙̃ͤ͂̾̆ ZA̡͊͠͝LGΌ ISͮ̂҉̯͈͕̹̘̱ TO͇̹̺ͅƝ̴ȳ̳ TH̘Ë͖́̉ ͠P̯͍̭O̚N̐Y̡ H̸̡̪̯ͨ͊̽̅̾̎Ȩ̬̩̾͛ͪ̈́̀́͘ ̶̧̨̱̹̭̯ͧ̾ͬC̷̙̲̝͖ͭ̏ͥͮ͟Oͮ͏̮̪̝͍M̲̖͊̒ͪͩͬ̚̚͜Ȇ̴̟̟͙̞ͩ͌͝S̨̥̫͎̭ͯ̿̔̀ͅParser un langage non contextuel
- Parsing manuel
- Parser combinator
- Parser generator
- Parser exotiques...
Les points d'attention
- Performance
- La gestion des erreurs
- Transformation du CST en AST
- Facilité d'utilisation
- Maintenabilité
Example... language a balise
[en]I'm in english[/en] [fr]Je suis en francais[/fr]
// What we expect
[
["en", "I'm in english", "en"],
["fr", "Je suis en francais", "fr"]
]
Vérifier l'équilibrage des balises rend le language contextuel !
Parser manuel
-
+Meilleurs performances (si on fait l'effort) -Non portable-
-Le moins maintenable (même si on fait l'effort) - par ex. le parser de C de Clang, le parser de Java de javac
Parser combinator
- Combinator = function prenant plusieurs parsers en entrée et renvoyant un parser en sortie
- On construit donc le parser du langage en combinant des parsers plus simples
Parsimmon
const OpeningTag = P.regex(/\[([a-z][a-z])\]/i, 1)
.desc("Opening tag [XX]");
const ClosingTag = P.regex(/\[\/([a-z][a-z])\]/i, 1)
.desc("Closing tag [XX]");
const Text = P.regex(/.*?(?=\[)/)
.desc("Text without [");
const Language = OpeningTag.chain(opening =>
Text.chain(text =>
ClosingTag.map(closing => [opening, text, closing]);
);
);
const Languages = Language.sepBy(P.optWhitespace)
Parser combinator
-
+Bonne maintenabilité, en particulier si on connait la programmation fonctionnelle +"Facile" à debugger+Pas d'étape de build intermédiaire~Mix AST et CST-Mauvaises performances-Non portable
Parser generator
- Grammaire dans un format spécifique (DSL)
- Génère un parser à partir de la grammaire
Example Nearley
@{%
const moo = require("moo");
const lexer = moo.compile({
openingTag:{ match:/\[[a-zA-Z][a-zA-Z]\]/,
value: s => s.slice(1,-1).toLowerCase()},
closingTag:{ match:/\[\/[a-zA-Z][a-zA-Z]\]/,
value: s => s.slice(2,-1).toLowerCase()},
ws: {match: /\s+/, lineBreaks: true},
text: {match:/.*?(?=\[)/},});
%}
@lexer lexer
languages -> openAndCloseTag (%ws:? openAndCloseTag):* {%
([head, tail]) =>
[head, ...tail.map(([,t]) => t)] %}
openAndCloseTag-> %openingTag %text %closingTag {%
(d) => [d[0].value, d[1].value, d[2].value] %}
Example AntlR
grammar langAntlr;
languages: openAndCloseTag (openAndCloseTag)* ;
openAndCloseTag: openingTag text closingTag ;
openingTag: OPENING_TAG ;
closingTag: CLOSING_TAG ;
text: TEXT ;
OPENING_TAG: '[' [a-zA-Z] [a-zA-Z] ']' ;
CLOSING_TAG: '[/' [a-zA-Z] [a-zA-Z] ']' ;
TEXT: CHAR+ ;
fragment CHAR: ~'[' ;
WHITESPACE : [ \t\n\r]+ -> skip ;
Visitor Pattern
class Visitor extends LangAntlrVisitor {
visitLanguages(ctx) {
return super.visitLanguages(ctx);
}
visitOpenAndCloseTag(ctx) {
return super.visitOpenAndCloseTag(ctx);
}
visitClosingTag(ctx) {
return ctx.getText().slice(2, -1);
}
visitOpeningTag(ctx) {
return ctx.getText().slice(1, -1);
}
visitText(ctx) {
return ctx.getText();
}
}
Parser Generator
+Performance+Portabilité-Maintenabilité-Étape de build
Backus Naur Form aka BNF
EBNF, ABNF (RFC 5234), etc.
begin-array = ws %x5B ws ; [ left square bracket
end-array = ws %x5D ws ; ] right square bracket
value-separator = ws %x2C ws ; , comma
quotation-mark = %x22 ; "
ws = *(%x20) ; space
null = %x6e.75.6c.6c ; null
value = null / array / string
string = quotation-mark *char quotation-mark
array = begin-array [
value *( value-separator value )
] end-array
Autres fonctionnalités...
-
Rails
- Outillage de debug/test
- Support IDE
- Génération de chaine valide
Famille de grammaire/algo
- LL(1), LL(k), LL(*)
- LR(1), LR(k) SLR(1), LALR(1)
- Peg
- Earley
On s'en moque
ChatGPT n'est pas un parser
Mais il peut écrire le parser
Act as a TypeScript expert.
Answer only with code, don't give any explanation.
Create a parser based on the Parsimmon Library
that can parse the language made of the following token:
* opening tag starting with `[` ,
followed by 2 lowercase letters,
ending with `]`
* closing tag starting with `[/`,
followed by 2 lowercase letters,
ending with `]`
* an arbitrary text in between those 2 tags
eg.
`[en]a text[/en] [fr]un texte[/fr]` should return
`[ ['en', 'a text', 'en'], ['fr', 'un texte', 'fr']]`
ChatGPT écrit un parser
import * as P from 'parsimmon';
const openingTag = P.string('[')
.then(P.regex(/[a-z]{2}/))
.skip(P.string(']'));
const closingTag = P.string('[/')
.then(P.regex(/[a-z]{2}/))
.skip(P.string(']'));
const text = P.takeWhile(c => c !== '[');
const tagParser = openingTag.chain(opening => {
return text.chain(content => {
return closingTag.map(closing => {
return [opening, content, closing];
});
});
});
Conclusion
Avez vous besoin d'un parser ?
- Vous avez déjà un parser composé de pleins de regex
- Vous acceptez en input un format texte
Conclusion
Quel parser choisir ?
- Tester les !
- Si simple et performance ne compte pas, parser combinator
- Si moins simple ou que les perfs sont importantes, parser generator
- Se focaliser sur la maintenabilité